Pushkin contest
The resulting project of Ruby courses.
Objective
Again dedicated server sends us questions and our clients have to respond answers.
There are 8 levels. You have to answer 100 questions to jump to another level.
Level 1:
Question: One line from any verse.
Answer: The title of the verse.
Level 2:
Question: One line from any verse with one word replaced by %WORD%.
Answer: Replaced word.
Level 3:
Question: Two lines in succession from any verse with one word replaced by %WORD% on each line.
Answer: Two replaced words separated by comma.
Level 4:
Question: Three lines in succession from any verse with one word replaced by %WORD% on each line.
Answer: Three replaced words separated by commas.
Level 5:
Question: One line from any verse with one word replaced by any other word from Pushkin’s vocabulary.
Answer: Right word and replaced one separated by comma.
Level 6:
Question: One line from any verse with shuffled words order (punctuation removed).
Answer: Original line.
Level 7:
Question: One line from any verse with shuffled letters order (punctuation removed).
Answer: Original line.
Level 8:
Question: One line from any verse with shuffled letters order (punctuation removed) and one letter changed.
Answer: Original line.
Source code
# config.ru
require 'rack'
require_relative 'pushkin-contest-bot'
run PushkinContestBot.new
# pushkin-contest-bot.rb
require 'benchmark'
require 'json'
require 'yaml'
require 'logger'
require 'net/http'
require_relative 'lib/pushkin'
include Benchmark
TOKEN = '7cb21edad8e21d1abf2147b12f89f276'.freeze
MY_URI = URI('http://pushkin.rubyroidlabs.com/quiz')
LOGFILE = 'pushkin.log'
LYRICS = 'lyrics.yml'
LEVELS = 8
class PushkinContestBot
def initialize
@count = [0] * (LEVELS + 1)
@time = [Tms.new] * (LEVELS + 1)
@logger = Logger.new(LOGFILE, level: :info)
@logger.formatter = proc { |severity, datetime, progname, msg| "#{msg}\n" }
@pushkin = Pushkin.new
verses = []
@logger.info " Lyrics:#{LYRICS}"
time = measure { verses = YAML.load(File.read(LYRICS)) }
@logger.info "Load YAML:#{time}".chomp
time = measure { verses.each { |verse| @pushkin.add(verse[0], verse[1]) }}
@logger.info "Add2array:#{time}".chomp
time = measure { @pushkin.init_hash }
@logger.info "Init hash:#{time}".chomp
end
def call(env)
return results if env['REQUEST_METHOD'] == 'GET'
answer = 'нет'
request = JSON(env['rack.input'].read)
question = request['question']
id = request['id']
level = request['level']
time = measure do
answer = case level
when 1
@pushkin.run_level1(question)
when 2
@pushkin.run_level2(question)
when 3
@pushkin.run_level3(question)
when 4
@pushkin.run_level4(question)
when 5
@pushkin.run_level5(question)
when 6
@pushkin.run_level6(question)
when 7
@pushkin.run_level7(question)
when 8
@pushkin.run_level8(question)
end
end
@time[level] += time
@count[level] += 1
@logger.info " Level #{level}:#{@count[level]}"
@logger.info "Question:#{question}"
@logger.info " Answer:#{answer}"
@logger.info " Time:#{@time[level]}"
parameters = { answer: answer, token: TOKEN, task_id: id }
Net::HTTP.post_form(MY_URI, parameters)
[200, {}, []]
end
def results
txt = (1..LEVELS).map { |i| "Level #{i}:#{@count[i]} => #{@time[i]}" }
txt << " Total:#{@count.sum} => #{@time.reduce(:+)}"
[200, {'Content-Type' => 'text/plain'}, txt]
end
end
# lib/pushkin.rb
require_relative 'verse'
class Pushkin
def initialize
@verses = [] # all verses
@hash2line_orig = {} # line hash => "line"
@hash2word = {} # word hash => "word"
@hash2title = {} # line hash => "title"
@wc2lineh = {} # words count => [line hash]
@next_line = {} # line hash => next line hash
@hash2words_arr = {} # line hash => [word hash]
@hash2chars_arr = {} # line hash => [char hash]
@cc2lineh = {} # chars count => [line hash]
end
def add(title, text)
@verses << Verse.new(title, text)
end
def run_level1(question)
line = question.scan(/[\p{Word}\-]+/).join(' ')
@hash2title[line.hash]
end
def run_level2(question)
line = question.sub('%WORD%', 'WORD')
words_count = line.scan(/[\p{Word}\-]+/).size
query = Regexp.new(line.sub('WORD','([\p{Word}]+)'))
@wc2lineh[words_count].each do |line_hash|
query.match(@hash2line_orig[line_hash]) do |word|
return word[1]
end
end
'нет'
end
def run_level3(question)
lines = question.split("\n")
return run_level2(question) if lines.size == 1
lines.map! { |line| line.sub('%WORD%', 'WORD') }
words_count = lines.first.scan(/[\p{Word}\-]+/).size
query = lines.map { |line| Regexp.new(line.sub('WORD','([\p{Word}]+)')) }
@wc2lineh[words_count].each do |lh|
query[0].match(@hash2line_orig[lh]) do |word1|
query[1].match(@hash2line_orig[@next_line[lh]]) do |word2|
return "#{word1[1]},#{word2[1]}"
end
end
end
'нет'
end
def run_level4(question)
lines = question.split("\n")
return run_level3(question) if lines.size == 2
lines.map! { |line| line.sub('%WORD%', 'WORD') }
words_count = lines.first.scan(/[\p{Word}\-]+/).size
query = lines.map { |line| Regexp.new(line.sub('WORD','([\p{Word}]+)')) }
@wc2lineh[words_count].each do |lh|
query[0].match(@hash2line_orig[lh]) do |word1|
query[1].match(@hash2line_orig[@next_line[lh]]) do |word2|
query[2].match(@hash2line_orig[@next_line[@next_line[lh]]]) do |word3|
return "#{word1[1]},#{word2[1]},#{word3[1]}"
end
end
end
end
'нет'
end
def run_level5(question)
words = question.scan(/[\p{Word}\-]+/)
words_arr = words.map { |word| word.hash }
words_count = words.size
@wc2lineh[words_count].each do |line_hash|
diff1 = @hash2words_arr[line_hash] - words_arr
next if diff1.size > 1
diff2 = words_arr - @hash2words_arr[line_hash]
next if diff2.size > 1
return "#{@hash2word[diff1.first]},#{@hash2word[diff2.first]}"
end
'нет'
end
def run_level6(question)
chars_arr = question.scan(/./).map(&:hash)
chars_count = chars_arr.size
@cc2lineh[chars_count].each do |line_hash|
diff1 = @hash2chars_arr[line_hash] - chars_arr
next if diff1.any?
diff2 = chars_arr - @hash2chars_arr[line_hash]
next if diff2.any?
return @hash2line_orig[line_hash]
end
'нет'
end
def run_level7(question)
run_level6(question)
end
def run_level8(question)
chars_arr = question.scan(/./).map(&:hash)
chars_count = chars_arr.size
@cc2lineh[chars_count].each do |line_hash|
orig_arr = @hash2line_orig[line_hash].scan(/[\p{^Punct}\-]/).map(&:hash)
arr = Array.new(orig_arr)
diff1 = chars_arr.map { |i| (ind = arr.index(i)) ? (arr[ind] = nil) : i }
diff1.compact!
next if diff1.size > 1
diff2 = orig_arr.map { |i| (ind = chars_arr.index(i)) ? (chars_arr[ind] = nil) : i }
diff2.compact!
next if diff2.size > 1
return @hash2line_orig[line_hash]
end
'нет'
end
def to_s
str = ''
@verses.each do |v|
str << "#{v.title}\n\n"
v.lines_arr.each do |l|
str << "#{l.line}\n"
end
str << "\n\n"
end
str
end
# indexing @verses
def init_hash
prev = @verses[-1].lines_arr[-1].line_hash
@verses.each do |verse|
verse.lines_arr.each do |line|
# line hash => "line"
@hash2line_orig[line.line_hash] = line.line_orig
# line hash => "title"
@hash2title[line.line_hash] = verse.title
# words count => [line_hash]
@wc2lineh[line.words_count] ||= []
@wc2lineh[line.words_count] << line.line_hash
# line hash => next line hash
@next_line[prev] = line.line_hash
prev = line.line_hash
# word hash => "word"
line.words_arr.each do |wrd|
@hash2word[wrd.word_hash] = wrd.word
end
# line hash => [word_hash]
@hash2words_arr[line.line_hash] = line.words_arr.map { |word| word.word_hash }
# line hash => [char hash]
@hash2chars_arr[line.line_hash] = line.line_orig.scan(/[\p{^Punct}\-]/).map(&:hash)
# chars count => [line hash]
chars_count = @hash2chars_arr[line.line_hash].size
@cc2lineh[chars_count] ||= []
@cc2lineh[chars_count] << line.line_hash
end
end
@next_line[prev] = @verses[0].lines_arr[0].line_hash
end
end
# lib/verse.rb
require_relative 'line'
class Verse
attr_reader :title
attr_reader :lines_arr
def initialize(title, text)
@title = title
@lines_arr = text.map { |line| Line.new(line) }
end
end
# lib/line.rb
require_relative 'word'
class Line
attr_reader :line_orig
attr_reader :line
attr_reader :line_hash
attr_reader :words_count
attr_reader :words_arr
def initialize(line)
@line_orig = line
arr = line.scan(/[\p{Word}\-]+/) # array of words without punctuation
@line = arr.join(' ')
@line_hash = @line.hash
@words_arr = arr.map { |word| Word.new(word) }
@words_count = arr.size
end
end
# lib/word.rb
class Word
attr_reader :word
attr_reader :word_hash
attr_reader :word_length
attr_reader :chars_hash_arr
def initialize(word)
@word = word
@word_hash = word.hash
@word_length = word.length
@chars_hash_arr = word.scan(/./).map(&:hash)
end
end
# parse.rb
require 'benchmark'
require 'mechanize'
include Benchmark
URL = 'http://ilibrary.ru/author/pushkin/l.all/index.html'.freeze
agent = Mechanize.new
agent.user_agent_alias = 'Mac Safari'
verses = []
page = agent.get(URL)
links = page.xpath('//div[@class="list"]/p')
total = links.size
count = 1
total_time = Tms.new
benchmark(CAPTION, 11, FORMAT, ' Total time', 'Averge time') do |bm|
links.each do |link|
time = bm.report(format('%4d / %4d', count, total)) do
title = link.text.gsub(/ \(.*?\)/, '')
title.gsub!('', '')
title.gsub!(/\s+/, ' ')
quote = title.scan(/«(.*?)...»/)
title = quote[0][0] unless quote.empty?
url = "http://ilibrary.ru#{link.xpath('./a').attribute('href')}"
url.gsub!('index.html', 'p.1/index.html')
page = agent.get(url)
title2 = nil
begin
title2 ||= page.xpath('//div[@class="title"]/h1').text
title2 = title if title2.empty?
txt = page.xpath('//span[@class="vl"]')
if txt.any?
arr = []
txt.each do |i|
line = i.text
line.gsub!("\u0097", '—')
arr << line
end
verses << [title2, arr]
end
next_page = page.link_with(xpath: '//a[@title="Дальше"]')
page = next_page.click if next_page
end while next_page
count += 1
end
total_time += time
end
[total_time, total_time / (count - 1)]
end
File.open('lyrics.yml', 'w') { |f| f.write(YAML.dump(verses)) }
Results
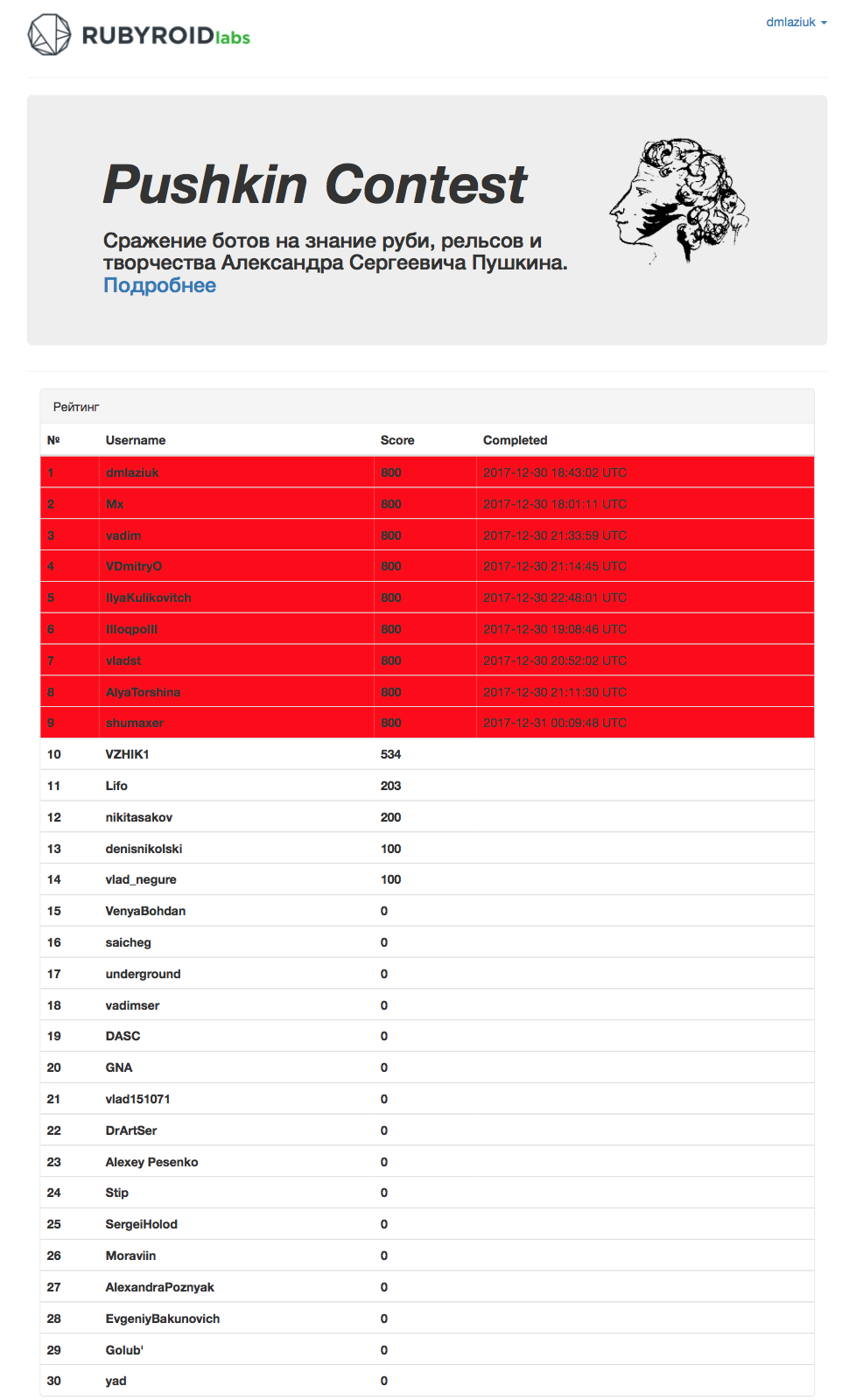
I took second place (my name is dmlaziuk). I’m very proud of it.
Here is the statistics for single run:
Level 1:100 => 0.000000 0.000000 0.000000 ( 0.004113)
Level 2:108 => 0.380000 0.004000 0.384000 ( 0.411866)
Level 3:116 => 0.624000 0.024000 0.648000 ( 0.610034)
Level 4:128 => 0.660000 0.024000 0.684000 ( 0.664425)
Level 5:133 => 1.592000 0.056000 1.648000 ( 1.662179)
Level 6:120 => 0.620000 0.028000 0.648000 ( 0.670100)
Level 7:112 => 0.516000 0.048000 0.564000 ( 0.556731)
Level 8:124 => 4.572000 0.024000 4.596000 ( 4.864457)
Total:943 => 9.300000 0.156000 9.456000 ( 9.433467)
And the statistics for real contest:
Level 1:715 => 0.028000 0.004000 0.032000 ( 0.030619)
Level 2:407 => 1.760000 0.088000 1.848000 ( 1.859254)
Level 3:166 => 0.876000 0.024000 0.900000 ( 0.903736)
Level 4:126 => 0.588000 0.028000 0.616000 ( 0.611655)
Level 5:144 => 0.920000 0.028000 0.948000 ( 0.986735)
Level 6:121 => 0.684000 0.032000 0.716000 ( 0.713213)
Level 7:118 => 0.564000 0.012000 0.576000 ( 0.613916)
Level 8:116 => 4.072000 0.036000 4.108000 ( 4.244934)
Total:1913 => 9.492000 0.252000 9.744000 ( 9.964062)
Total length of the contest was 3 hours for the first place. For me it took 3:40. The total processor run time was 9.96 seconds. The rest of time was internet infrastructure.
Source files are available on GitHub.



